ช่วงความเชื่อมั่น
ช่วงความเชื่อมั่นคืออะไร:
มันเป็นค่าประมาณของช่วงที่ใช้ในสถิติซึ่งมีพารามิเตอร์ประชากร พารามิเตอร์ประชากรที่ไม่รู้จักนี้พบได้จาก ตัวอย่างที่คำนวณจากข้อมูลที่รวบรวม
ตัวอย่าง: ค่าเฉลี่ยของตัวอย่างที่เก็บรวบรวมx̅อาจหรือไม่ตรงกับค่าเฉลี่ยประชากรจริงμ สำหรับสิ่งนี้เป็นไปได้ที่จะพิจารณาช่วงของค่าเฉลี่ยตัวอย่างที่ค่าเฉลี่ยประชากรนี้สามารถมีได้ ยิ่งช่วงเวลานี้นานขึ้นโอกาสที่จะเกิดเหตุการณ์นี้ก็ยิ่งมากขึ้นเท่านั้น
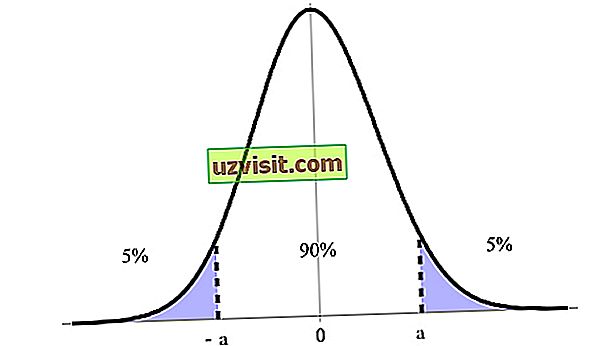
ช่วงความเชื่อมั่นจะแสดงเป็นเปอร์เซ็นต์ซึ่งแบ่งตามระดับความเชื่อมั่นโดย 90%, 95% และ 99% เป็นตัวบ่งชี้ที่มากที่สุด ตัวอย่างเช่นในภาพด้านล่างเรามีช่วงความมั่นใจ 90% ระหว่างขีด จำกัด บนและล่าง (a และ -a )
Confidence Interval เป็นหนึ่งในแนวคิดที่สำคัญที่สุดในการทดสอบสมมติฐานทางสถิติเพราะมันถูกใช้เป็นเครื่องวัดความไม่แน่นอน คำนี้นำเสนอโดยนักคณิตศาสตร์และนักสถิติชาวโปแลนด์ Jerzy Neyman ในปี 2480
Confidence Interval คืออะไร?
ช่วงความมั่นใจเป็นสิ่งสำคัญที่จะบ่งบอกถึงความไม่แน่นอน (หรือความไม่แน่นอน) กับการคำนวณ การคำนวณนี้ใช้ตัวอย่างการศึกษาเพื่อประเมินขนาดที่แท้จริงของผลลัพธ์ในประชากรต้นทาง
การคำนวณช่วงความมั่นใจเป็นกลยุทธ์ที่พิจารณาการสุ่มตัวอย่างข้อผิดพลาด ขนาดของผลลัพธ์ของการศึกษาของคุณและช่วงความมั่นใจของคุณเป็นลักษณะของค่าที่สันนิษฐานสำหรับประชากรดั้งเดิม
ยิ่งช่วงเวลาความเชื่อมั่นแคบลงความน่าจะเป็นที่เปอร์เซ็นต์ของประชากรการศึกษาจะแสดงถึงจำนวนที่แท้จริงของประชากรต้นทางให้ความมั่นใจมากขึ้นกับผลลัพธ์ของวัตถุการศึกษา
จะตีความช่วงความมั่นใจได้อย่างไร
การตีความที่ถูกต้องของช่วงความมั่นใจอาจเป็นสิ่งที่ท้าทายที่สุดของแนวคิดทางสถิตินี้ ตัวอย่างของการตีความแนวคิดที่พบบ่อยที่สุดคือ:
มี ความน่าจะ เป็น 95% ที่ในอนาคตมูลค่าที่แท้จริงของพารามิเตอร์ประชากร (เช่นค่าเฉลี่ย) จะอยู่ในช่วง X (ขีด จำกัด ล่าง) และ Y (ขีด จำกัด สูงสุด)
ดังนั้นช่วงความเชื่อมั่นจะถูกตีความดังนี้: มัน เป็น 95% มั่นใจว่าช่วงเวลาระหว่าง X (ขอบเขตล่าง) และ Y (ขอบเขตบน) มีค่าที่แท้จริงของพารามิเตอร์ประชากร
มันจะ ไม่ถูกต้องโดยสิ้นเชิงที่จะ ระบุว่า: มีความน่าจะเป็น 95% ที่ช่วงเวลาระหว่าง X (ขอบเขตล่าง) และ Y (ขอบเขตบน) มีค่าจริงของพารามิเตอร์ประชากร
ข้อความข้างต้นเป็นความเข้าใจผิดที่พบบ่อยที่สุดเกี่ยวกับช่วงความมั่นใจ หลังจากคำนวณช่วงสถิติแล้วสามารถมีได้เฉพาะพารามิเตอร์ประชากรหรือไม่
อย่างไรก็ตามช่วงเวลาอาจแตกต่างกันระหว่างกลุ่มตัวอย่างในขณะที่พารามิเตอร์ประชากรจริงเหมือนกันโดยไม่คำนึงถึงตัวอย่าง
ดังนั้นคำสั่งมั่นใจช่วงความมั่นใจสามารถทำได้เฉพาะในกรณีที่ช่วงความเชื่อมั่นจะถูกคำนวณใหม่สำหรับจำนวนตัวอย่าง
ขั้นตอนการคำนวณ Confidence Interval
ช่วงถูกคำนวณโดยใช้ขั้นตอนต่อไปนี้:
- รวบรวมข้อมูลตัวอย่าง: n ;
- คำนวณค่าเฉลี่ยตัวอย่าง x̅;
- พิจารณาว่าค่าเบี่ยงเบนมาตรฐานประชากร ( σ ) เป็นที่รู้จักหรือไม่ทราบ
- หากทราบค่าความเบี่ยงเบนมาตรฐานของประชากรสามารถใช้จุด z สำหรับระดับความเชื่อมั่นที่สอดคล้องกัน
- หากไม่ทราบค่าเบี่ยงเบนมาตรฐานประชากรเราสามารถใช้สถิติ t สำหรับระดับความเชื่อมั่นที่สอดคล้องกัน
- ดังนั้นพบขีด จำกัด ล่างและบนของช่วงความมั่นใจโดยใช้สูตรต่อไปนี้:
a) ค่าเบี่ยงเบนมาตรฐานของประชากรที่รู้จัก :
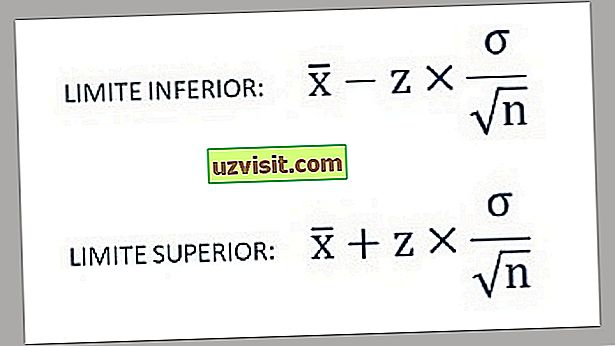
สูตรสำหรับการคำนวณค่าเบี่ยงเบนมาตรฐานของประชากรที่รู้จัก
b) ค่าเบี่ยงเบนมาตรฐานของประชากรที่ไม่รู้จัก :

สูตรสำหรับการคำนวณค่าเบี่ยงเบนมาตรฐานของประชากรที่ไม่รู้จัก
ตัวอย่างการปฏิบัติของช่วงความมั่นใจ
การศึกษาทางคลินิกประเมินความสัมพันธ์ระหว่างการปรากฏตัวของโรคหอบหืดและความเสี่ยงของการพัฒนาหยุดหายใจขณะหลับในผู้ใหญ่
ผู้ใหญ่บางคนถูกสุ่มเลือกจากรายชื่อเจ้าหน้าที่รัฐที่ต้องติดตามเป็นเวลาสี่ปี
ผู้เข้าร่วมกับโรคหอบหืดเมื่อเปรียบเทียบกับผู้ที่ไม่มีความเสี่ยงในการพัฒนาหยุดหายใจขณะหลับในสี่ปี
ในการดำเนินการวิจัยทางคลินิกเช่นตัวอย่างนี้กลุ่มย่อยของประชากรที่สนใจมักจะถูกคัดเลือกเพื่อเพิ่มประสิทธิภาพการศึกษา (ค่าใช้จ่ายน้อยลงและใช้เวลาน้อยลง)
กลุ่มย่อยของบุคคลนี้ประชากรที่ศึกษาประกอบด้วยผู้ที่ตรงตามเกณฑ์การรวมและตกลงที่จะมีส่วนร่วมในการศึกษาดังที่แสดงในภาพด้านล่าง

จากนั้นการศึกษาจะเสร็จสิ้นและคำนวณขนาดของผลกระทบ (ตัวอย่างเช่น ความแตกต่างเฉลี่ย หรือ ความเสี่ยงสัมพัทธ์ ) เพื่อตอบคำถามการวิจัย
กระบวนการนี้เรียกว่าการ อนุมาน เกี่ยวข้องกับการใช้ข้อมูลที่รวบรวมจากประชากรที่ศึกษาเพื่อประเมินขนาดของผลกระทบที่เกิดขึ้นจริงต่อประชากรที่น่าสนใจนั่นคือประชากรของแหล่งกำเนิด
ในตัวอย่างที่ได้รับนักวิจัยได้คัดเลือกตัวอย่างของพนักงานของรัฐ (ประชากรแหล่ง) ที่มีสิทธิ์และตกลงที่จะมีส่วนร่วมในการศึกษา (ประชากรการศึกษา) และรายงานว่าโรคหอบหืดเพิ่มความเสี่ยงของการหยุดหายใจขณะหลับในประชากรการศึกษา
ในการบัญชีสำหรับข้อผิดพลาดการสุ่มตัวอย่างเนื่องจากการรับสมัครเพียงกลุ่มย่อยของประชากรที่น่าสนใจพวกเขายังคำนวณ ช่วงความเชื่อมั่น 95% (รอบประมาณการ) ที่ 1.06 - 1.82 แสดงถึงความน่าจะเป็น 95 % ที่ความเสี่ยงสัมพัทธ์ที่แท้จริงในประชากรต้นทางจะอยู่ระหว่าง 1.06 ถึง 1.82
ช่วงความเชื่อมั่นสำหรับค่าเฉลี่ย
เมื่อมีข้อมูลของค่าเบี่ยงเบนมาตรฐานของประชากรเราสามารถคำนวณช่วงความเชื่อมั่นสำหรับค่าเฉลี่ยหรือค่าเฉลี่ยของประชากรนั้น
เมื่อคุณลักษณะทางสถิติที่ถูกวัด (เช่นรายได้ IQ ราคาส่วนสูงปริมาณหรือน้ำหนัก) เป็นตัวเลขในกรณีส่วนใหญ่คาดว่ามูลค่าเฉลี่ยของประชากรจะพบ
ดังนั้นเราจึงพยายามหาค่าเฉลี่ยประชากร ( μ ) โดยใช้ค่าเฉลี่ยตัวอย่าง ( x̅ ) ด้วยระยะขอบของข้อผิดพลาด ผลลัพธ์ของการคำนวณนี้เรียกว่า ช่วงความเชื่อมั่นสำหรับค่าเฉลี่ยประชากร
เมื่อทราบค่าเบี่ยงเบนมาตรฐานของประชากรสูตรสำหรับช่วงความมั่นใจ (CI) สำหรับค่าเฉลี่ยของประชากรคือ:

ที่อยู่:
- x̅ คือค่าเฉลี่ยตัวอย่าง;
- σ คือค่าเบี่ยงเบนมาตรฐานประชากร
- n คือขนาดตัวอย่าง;
- Ζ * แทนค่าที่เหมาะสมของการแจกแจงแบบปกติมาตรฐานสำหรับระดับความมั่นใจที่คุณต้องการ
ต่อไปนี้เป็นค่าสำหรับระดับความเชื่อมั่นต่างๆ ( Ζ * ):
| ระดับความน่าเชื่อถือ | ค่าของ Z * - |
|---|---|
| 80% | 01:28 |
| 90% | 1.645 (ธรรมดา) |
| 95% | 1.96 |
| 98% | 02:33 |
| 99% | 02:58 |
ตารางด้านบนแสดงค่า z * สำหรับระดับความเชื่อมั่นที่ให้ไว้ โปรดทราบว่าค่าเหล่านี้ได้มาจากการแจกแจงแบบปกติมาตรฐาน (Z-)
พื้นที่ระหว่างแต่ละค่า z * และค่าลบของค่านี้คือเปอร์เซ็นต์ความเชื่อมั่น (โดยประมาณ) ตัวอย่างเช่นพื้นที่ระหว่าง z * = 1.28 และ z = -1.28 มีค่าประมาณ 0.80 ดังนั้นตารางนี้ยังสามารถขยายเป็นเปอร์เซ็นต์ความเชื่อมั่นอื่น ๆ ตารางแสดงเปอร์เซ็นต์ความไว้วางใจที่ใช้กันมากที่สุดเท่านั้น
ดูความหมายของสมมติฐาน